首页
关于
论坛
R会
投稿
搜索
统计之都
最近更新于2024-04-15
45 / 52
统计软件
Sweave:打造一个可重复的统计研究流程
谢益辉
/
2010-11-05
警告:本文提到的工具在更新中,请暂时不要按本文的配置去做,静候LyX 2.0.3的发布。 我们都痛恨统计造假。我们都对重复性的工作感到厌倦。如果你同意这两句话或这两句话适用于你的现状,那么本文将介绍一套开源、免费的工具来克服这两个问题。当然,前提是你愿意改变,这里的工具可以让这两种现象没有藏身之地,但无法改变造假和重复劳动的现实。以下为吊胃口视频(墙外观众可以看Vimeo;墙内看不到视频的可以任选……
统计模型
强大数定律与康托三分集
左辰
/
2010-10-13
首先从博雷尔正轨数定律(Borel’s Normal Number Theorem)说起。众所周知,(0,1]区间上的每一个实数\(\omega\)都与一列唯一的无穷的二进制展开序列\(\{X_k(\omega)\}\)一一对应,其中\(X_k (\omega)\)表示二进制展开的第k位,对应关系为: $$ \omega=\sum_{k=1}^n\frac{X_k(\omega)}{2^k} $$……
机器学习
LDA主题模型简介
范建宁
/
2010-10-08
上个学期到现在陆陆续续研究了一下主题模型(topic model)这个东东。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。 D. M. Blei在2003年(准确地说应该是2002年)提出的LDA(Latent……
R语言
用R也能做精算——actuar包学习笔记(二)
李皞
/
2010-09-18
本次发布的是actuar包学习笔记的第二部分。 时隔第一篇文章的发布已经一年之久,期间断断续续写了一些,也终于能拿得出一小部分成果。actuar包作为一个精算包,其处理分布的功能非常强大,因此我想不仅是精算领域,在其他应用领域需要对分布进行处理时,也可以应用这个工具。 本次更新包扩两个部分: 1)对actuar包学习笔记(一)的内容进行补充和完善,并将其按小节拆分成两个部分actuar包学习笔记(……
新闻动态
北京数据管理与生物统计论坛(BBF)第三次聚会见闻录
胡江堂
/
2010-09-05
9月4号下午,周六,去北大医学部参加了北京数据管理与生物统计论坛(Beijing Biometrics Forum, BBF)的第三次聚会,这次活动由SAS China和北京大学临床研究所赞助。这里写些会议见闻和一些零散的感想,不算是会议的正式“纪要”。东西贴这,大致想给“统计之都”(COS)的朋友交流下北京SAS技术社区的氛围、工作市场情况以及一些相关技术评论等等。 […] 西安杨……
统计模型
泊松低方差计数数据建模问题
饶燕芳
/
2010-08-28
本文作者为中国人民大学统计学院饶燕芳同学,由COS编辑部审核发表,略有修改。点击此处下载/阅读本文PDF版本 […] 在数据分析和数据建模的过程中,我们通常需要假定数据变量服从某种分布,以便于建立与分布参数有关的模型或方程,之后利用观测值对参数进行估计,从而达到研究和分析的目的。由于变量是随机的,我们无法确定变量在某个情况下的具体取值,因此通过假定它服从某个分布,然而感兴趣的只是它们……
R会议
第三届中国R语言会议(北京会场)纪要
邱怡轩
/
2010-06-23
第三届中国R语言会议北京会场合影(右键另存为看大图) 第三届中国R语言会议(北京会场)于2010年6月14日~15日在中国人民大学明德法学楼0101成功召开。会议由中国人民大学应用统计科学研究中心与中国人民大学统计学院主办、统计之都网站(cos.name)协办。在两天的会议时间里,来自各行各业的R用户齐聚北京,共同探讨和交流R软件的使用经验,取得了丰厚的成果。 […] 本次会议吸引……
统计模型
从中心极限定理的模拟到正态分布
谢益辉
/
2010-05-09
昨日翻看朱世武老师的《金融计算与建模》幻灯片(来源,幻灯片“13随机模拟基础”),其中提到了中心极限定理(Central Limit Theorem,下文简称CLT)及其SAS模拟实现。由于我一直觉得我们看到的大多数对CLT的模拟都有共同的误导性,因此在此撰文讲述我的观点,希望能说清楚CLT的真实面目,让读者对它有更深刻的理解。 […] 从广义的角度来讲,CLT说的是一些随机变量之……
统计软件
Think SAS(一)
胡江堂
/
2010-04-18
为什么你应该学SAS?本文不想卷入SAS与R,或者与SPSS、S-Plus、Matlab等统计软件孰优孰劣的争论中去,我是说,作为一个有志于投身工业界的统计分析人员,你为什么应该把SAS纳入你的分析工具箱?这会是一篇动员贴,尤其是对广大对数据分析感兴趣的在校生。在默认统计编程语言是R的“统计之都”,我需要拿上面这幅图来吸引眼球:学SAS吧。 R是好东西,不只是在COS,现在全世界的统计系和统计学……
统计应用
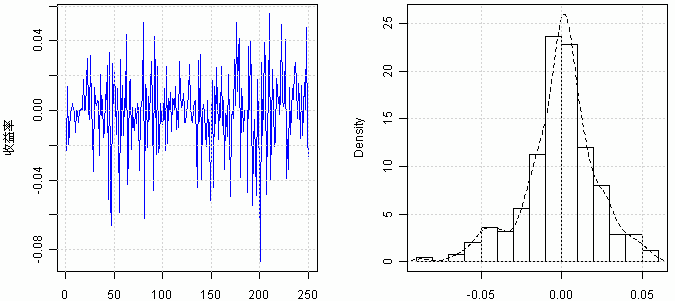
我国黄金期货市场的VaR风险度量——基于历史模拟法
邓一硕
/
2010-04-14
VaR(Value at Risk)是上世纪90年代由JP·Morgan公司在风险矩阵中提出的一种新型风险管理工具,VaR定义简单,计算简便具有很高的实用价值。因此,VaR自诞生以来就在金融领域得到了广泛的应用,且目前在全世界已发展成为金融市场风险测量的主流方法。 […] VaR全称为Value at Risk,统译为“在险价值”。其是指:在市场正常波动情况下,在指定的概率水平(置信……
统计计算
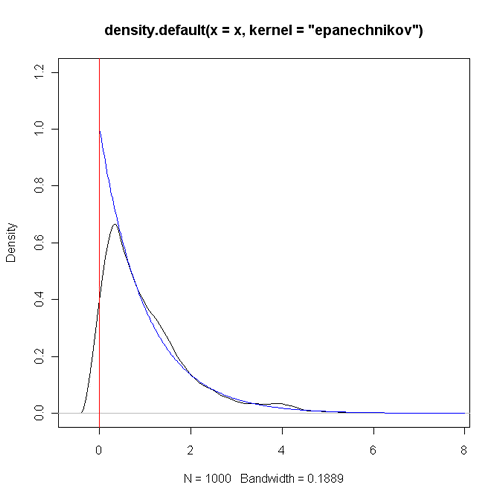
有边界区间上的核密度估计
邱怡轩
/
2010-04-11
核密度估计应该是大家常用的一种非参数密度估计方法,从某种程度上来说它的性质比直方图更好,可以替代直方图来展示数据的密度分布。但是相信大家会经常遇到一个问题,那就是有些数据是严格大于或等于零的,在这种情况下,零附近的密度估计往往会出现不理想的情况。下面以一个指数分布的模拟数据为例(样本量为1000),R程序代码为: set.seed(123) x <- rexp(1000, 1)……
统计计算
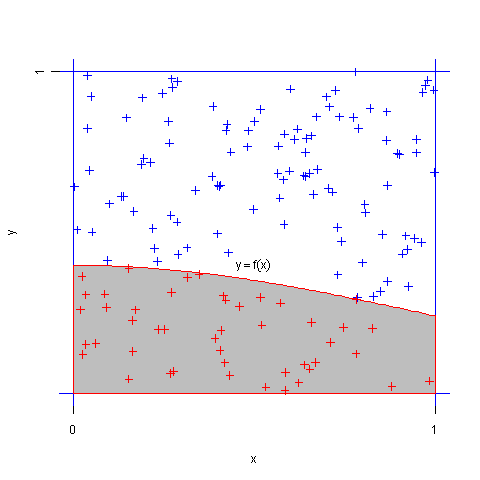
蒙特卡洛方法与定积分计算
邓一硕
/
2010-03-08
本文讲述一下蒙特卡洛模拟方法与定积分计算,首先从一个题目开始:设\(0\leq f(x) \leq 1\),用蒙特卡洛模拟法求定积分\(J=\int_{0}^{1}f(x)dx\)的值。 […] 设\((X,Y)\)服从正方形 \(\{0\leq x \leq 1,0\leq y\leq 1\}\)上的均匀分布,则可知 \(X,Y\)分别服从[0,1]上的均匀分布,且\(X,Y\)相……
««
«
43
44
45
46
47
»
»»