首页
关于
论坛
R会
投稿
搜索
回归
最近更新于2024-04-15
1 / 1
统计计算
共轭梯度法计算回归
邱怡轩
/
2016-11-23
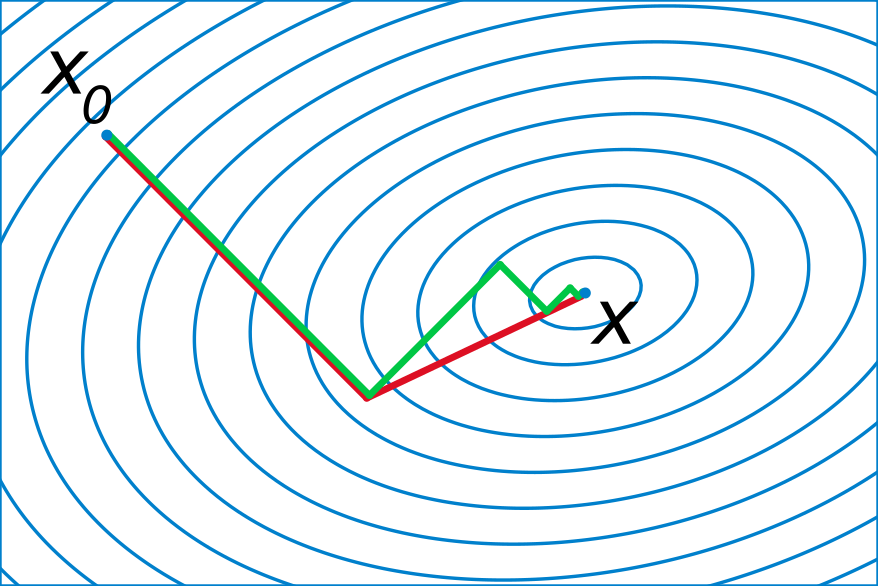
轮回眼 共轭梯度示意图(图片来源:维基百科) […] 之所以写这篇文章,是因为前几天统计之都的微信群里有同学提了一个问题,想要对一个很大的数据集做回归。然后大家纷纷给出了自己的建议,而我觉得共轭梯度算回归的方法跟这个背景比较契合,所以就正好写成一篇小文,与大家分享一下。 说到算回归,或许大家都会觉得这个问题太过简单了,如果用 $X$ 表示自变量矩阵,$y$ 表示因变量向量,那么回归……
统计应用
标题党统计学
邱怡轩
/
2016-07-02
如果你是被这个标题骗进来的,那么说明标题党的存在的确是有原因的。 在网络高度发达(以及“大数据”泛滥)的今天,数据动不动就是以 GB 和 TB 的级别存储,然而相比之下,人类接受信息的速度却慢得可怕(参见大刘《乡村教师》)。 试想一下,你一分钟能阅读多少文字?一千?五千?总之是在 KB 的量级。 所以可以说,人们对文字的“下载速度”基本上就是 1~10KB/min。如果拿这个速度去上网的话你还能……
推荐文章
数据江湖,回归5式
王汉生
/
2016-06-04
今天要跟大家分享的主题叫做:数据江湖,回归5式! 如今啊,大数据时代,群雄割据,天下大乱。各位童鞋,闯荡江湖,凶险难测。没一些必备的看家的本领,就想从数据出发,直达价值的彼岸,恐怕很难。 为此呢,熊大教大家几招防身绝技,叫做:回归5式!简单的说,就是5种最常见的回归模型。这5个招式,看似简单,却是熊大行走江湖的看家本领。回归5式,就如同少林长拳,看似平淡无奇,但是如果辅以深厚的内力,就能威力无比。……
统计软件
极简 Spark 入门笔记——安装和第一个回归程序
邱怡轩
/
2015-04-22
现在的各种数据处理技术更新换代太快,新的名词和工具层出不穷,像是 Hadoop 和 Spark 这些,最近几年着实火了一把。事实上听说 Spark 也有一段时间了,但一直是只闻其名不见其实,今天就来简单记录一下初学 Spark 的若干点滴。 […] 按照 Spark 官方的说法,Spark 是一个快速的集群运算平台,以及一系列处理大型数据集的工具包。用通俗的话说,Spark 与 R ……
统计模型
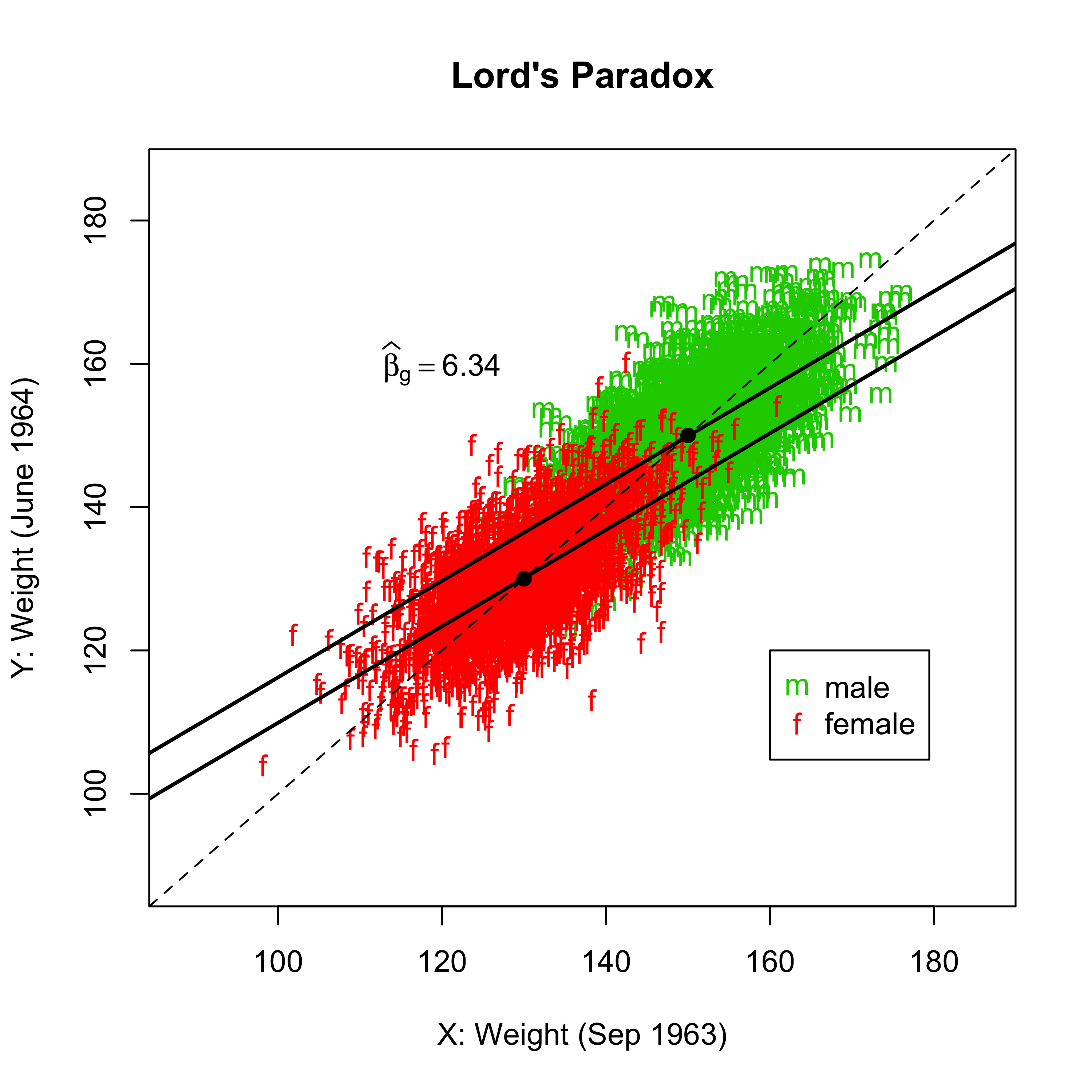
因果推断简介之七:Lord’s Paradox
丁鹏
/
2013-09-09
$$ \def\ind{{\perp\!\!\!\perp}} \def\nind{{\not\!\perp\!\!\!\perp}} $$ 在充满随机性的统计世界中,悖论无处不在。这一节介绍一个很有名,但是在中文统计教科书中几乎从未介绍过的悖论。这个悖论是 Educational Testing Service (ETS) 的统计学家 Frederic Lord 于 1967 年提出来的;最终由……
统计计算
R 中大型数据集的回归
邱怡轩
/
2013-08-26
原文地址:http://statr.me/2011/10/large-regression/ […] 众所周知,R 是一个依赖于内存的软件,就是说一般情况下,数据集都会被整个地复制到内存之中再被处理。对于小型或者中型的数据集,这样处理当然没有什么问题。但是对于大型的数据集,例如网上抓取的金融类型时间序列数据或者一些日志数据,这样做就有很多因为内存不足导致的问题了。 这里是一个具体的例……
统计模型
分组最小角回归算法(group LARS)
郝智恒
/
2011-04-27
继续前两篇博文中对于最小角回归(LARS)和lasso的介绍。在这篇文章中,我打算介绍一下分组最小角回归算法(Group LARS)。本文的主要观点均来自Ming Yuan和Yi Lin二人2006合作发表在JRSSB上的论文Model selection and estimation in regression with grouped variables. 首先,我想说明一下,为何要引入分组变……
推荐文章
我的一些统计方法观(写给在统计学院学习的学弟学妹之三)
谢益辉
/
2008-11-29
记得高中很讨厌政治课,但是有几个词烙在脑子里,想忘都忘不掉,比如“世界观”和“方法论”,当时那位老爷爷整天给我们灌输这些玩意儿,搞得我现在对这些词汇仍然如鬼神般敬而远之。这次我要写的是关于统计方法的一些思考(主要是思路),但又不太多涉及方法本身的推导证明,因此只好称之为“方法观”。 现在每天感慨统计领域太宽,模型太多,方法太杂,让人把握不住方向。不过上次高校研究生统计论坛我仍然不知天高地厚地选了一……
统计图形
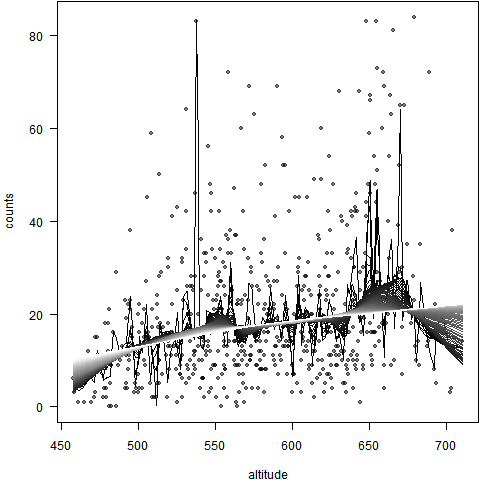
用局部加权回归散点平滑法观察二维变量之间的关系
谢益辉
/
2008-11-26
二维变量之间的关系研究是很多统计方法的基础,例如回归分析通常会从一元回归讲起,然后再扩展到多元情况。局部加权回归散点平滑法(locally weighted scatterplot smoothing,LOWESS或LOESS)是查看二维变量之间关系的一种有力工具。 LOWESS主要思想是取一定比例的局部数据,在这部分子集中拟合多项式回归曲线,这样我们便可以观察到数据在局部展现出来的规律和趋势;……